StarTree Cube
Introduction
StarTree Cubes are materialized pre-aggregation results stored as tables. This technique is built to optimize low latency iceberg queries. Iceberg queries are a special case of SQL queries involving GROUP BY and HAVING clauses, wherein the answer set is small relative to the data scanned size. Queries can be characterized by their huge input-small output.
This technique allows user to build Cubes on an existing table with aggregates and dimensions that are intended to optimize specific queries. Cubes are rollup pre-aggregations that have fewer dimensions and rows compared to the original table. Smaller number of rows means the time spent on table scan is significantly reduced which in turn reduces query latency. If a query is a subset of dimensions and measures of the pre-aggregated table, then Cube can be used to calculate the query without accessing the original table.
Few of the Cube properties are
- Cubes are stored in tabular format
- Generally speaking, Cubes can be created for any table in any connector and stored in another connector
- Query latency is reduced by rewriting the logical plan to use Cube instead of the original table.
Cube Optimizer Rule
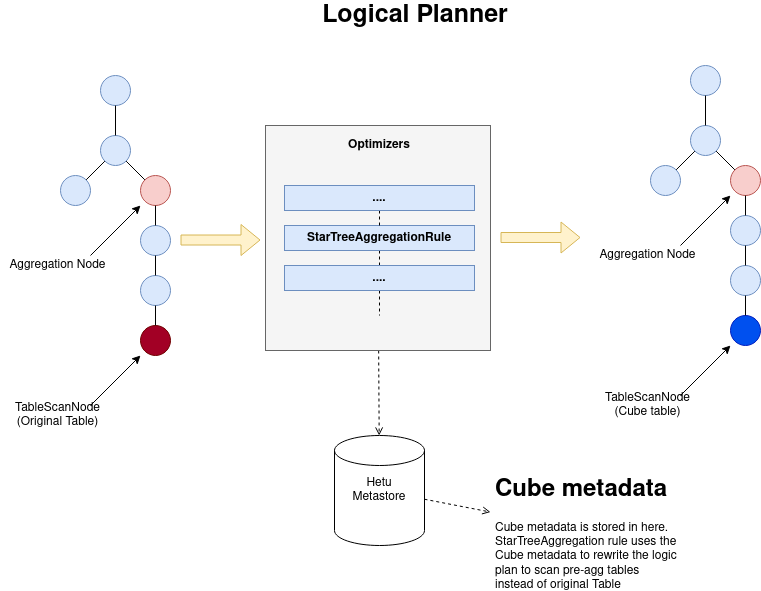
As part of logical plan optimization, Cube optimizer rule analyzes and optimizes the aggregation subtree of the logical plan with Cubes. The rule looks for the aggregation subtree that typically looks like the following
AggregationNode
|- ProjectNode[Optional]
|- ProjectNode[Optional]
|- FilterNode[Optional]
|- ProjectNode[Optional]
|- TableScanNode
The rule parses through the subtree and identifies the table name, aggregate functions, where clause, group by clause that is matched with Cube metadata to identify any Cube that can help optimize the query. In case of multiple match, recently created Cube is selected for optimization. If any match found, entire aggregation subtree is rewritten using the Cube. This optimizer uses the TupleDomain construct to match if predicates provided in the Query can be supported by the Cubes.
The following picture depicts the change in the logical plan after the optimization.
Recommended Usage
- Cubes are most useful for iceberg queries that takes huge input and produces small output.
- Query performance is best when size of the Cube is less that on the actual table on which Cube was built.
- Cubes need to be rebuilt if the source table is updated.
Note: If the source table is updated once the Cubes are built, Cube optimizer ignores the set of Cubes created on the table. Reason being, any operation on the update is considered as a change in the existing data even if only new rows are inserted on the original table. Since inserts and updates can’t be differentiated, Cubes can’t be used as it might result in incorrect result. We are working on a solution to overcome this limitation.
Supported Connectors
Star Tree Cube can be stored in following Connectors
- Hive
- Memory
Tables from following Connectors can be used as source to build a StarTree Cube.
- Hive
- Memory
- Clickhouse
Future Work
Support for more JDBC connectors
Simplify Cube management
2.1. Overcome the limitation of Creating Cube for larger dataset.
Enabling and Disabling StarTree Cube
To enable:
SET SESSION enable_star_tree_index=true;
To disable:
SET SESSION enable_star_tree_index=false;
Configuration Properties
| Property Name | Default Value | Required | Description |
|---|---|---|---|
| optimizer.enable-star-tree-index | false | No | Enables StarTree Cube |
| cube.metadata-cache-size | 50 | No | The maximum number of metadata for StarTree Cubes that could be loaded into cache before eviction happens |
| cube.metadata-cache-ttl | 1h | No | The maximum time to live of StarTree Cubes that are be loaded into cache before eviction happens |
Dependencies
StarTree Cube relies on Hetu Metastore to store the Cube related metadata. Please check Hetu Metastore for more information.
Examples
Creating a StarTree Cube:
CREATE CUBE nation_cube
ON nation
WITH (AGGREGATIONS=(count(*), count(distinct regionkey), avg(nationkey), max(regionkey)),
GROUP=(nationkey),
format='orc', partitioned_by=ARRAY['nationkey']);
Next, to add data to the Cube:
INSERT INTO CUBE nation_cube WHERE nationkey >= 5;
Creating a StarTree Cube with WHERE clause: Please note that the following query is only supported via the CLI
CREATE CUBE nation_cube
ON nation
WITH (AGGREGATIONS=(count(*), count(distinct regionkey), avg(nationkey), max(regionkey)),
GROUP=(nationkey),
format='orc', partitioned_by=ARRAY['nationkey'])
WHERE nationkey >= 5;
To use the new Cube, just query the original table using aggregations that were included in the Cube:
SELECT count(*) FROM nation WHERE nationkey >= 5 GROUP BY nationkey;
SELECT nationkey, avg(nationkey), max(regionkey) FROM nation WHERE nationkey >= 5 GROUP BY nationkey;
Since the data inserted into the Cube was for nationkey >= 5, only queries matching this condition will utilize the Cube.
Queries not matching the condition would continue to work but won’t use the Cube.
If the source table of a Cube gets updated, the corresponding Cube gets expired automatically. In order to overcome this issue, we have added support in openLooKeng CLI by introducing RELOAD CUBE command. The user will have the ability to manually reload a cube if the status of the Cube becomes INACTIVE or EXPIRED. The syntax to reload the Cube nation_cube is as follows,
RELOAD CUBE nation_cube
Please note that this feature is only supported via the CLI. During this reload process if an unexpected error occurs, the user will get to see the original SQL statement to recreate the cube manually.
Building Cube for Large Dataset
One of the limitations with the current implementation is that Cube cannot be built for a larger dataset at once. This is due to the cluster memory limitation. Processing large number of rows requires more memory than cluster is configured with. This results in query failing with message Query exceeded per-node user memory limit. To overcome this issue, INSERT INTO CUBE SQL support was added. The user has ability to build a Cube for larger data by executing multiple insert into Cube statements. The insert statement accepts a where clause, and it can be used to limit the number of processed and inserted into Cube.
This section explains the steps to build a Cube for larger dataset.
Let us take an example of TPCDS dataset and store_sales table. The table has 10 years worth of data and user wants to build a Cube for year 2001
and due to the cluster memory limit, the entire data set for year 2001 cannot be processed at once.
CREATE CUBE store_sales_cube ON store_sales WITH (AGGREGATIONS = (sum(ss_net_paid), sum(ss_sales_price), sum(ss_quantity)), GROUP = (ss_sold_date_sk, ss_store_sk));
SELECT min(d_date_sk) as year_start, max(d_date_sk) as year_end FROM date_dim WHERE d_year = 2001;
year_start | year_end
------------+----------
2451911 | 2452275
(1 row)
The following query could result in a failure if the number of rows need to be processed is huge and the query memory exceeds the limit configured for the cluster.
INSERT INTO CUBE store_sales_cube WHERE ss_sold_date_sk BETWEEN 2451911 AND 242275;
Solution 1)
To overcome this issue, multiple insert statements can be used to process rows and insert into Cube and the number of rows can be limited by using where clause;
INSERT INTO CUBE store_sales_cube WHERE ss_sold_date_sk BETWEEN 2451911 AND 2452010;
INSERT INTO CUBE store_sales_cube WHERE ss_sold_date_sk >= 2452011 AND ss_sold_date_sk <= 2452110;
INSERT INTO CUBE store_sales_cube WHERE ss_sold_date_sk BETWEEN 2452111 AND 2452210;
INSERT INTO CUBE store_sales_cube WHERE ss_sold_date_sk BETWEEN 2452211 AND 2452275;
Solution 2)
CLI has been modified to support creating Cubes for larger dataset and without need for multiple insert statements. CLI internally handles this process. Once the user runs create Cube statement with where clause, the CLI takes care of creating the Cube as well as inserting the data into it. This process improves the user experience and improves the memory footprint based on the cluster memory limits. CLI internally parses the converts the statement into one create Cube statement followed by one or more insert statements. This change is only works if user executes the command from CLI and not via any other means i.e. JDBC, etc…
CREATE CUBE store_sales_cube ON store_sales WITH (AGGREGATIONS = (sum(ss_net_paid), sum(ss_sales_price), sum(ss_quantity)), GROUP = (ss_sold_date_sk, ss_store_sk)) WHERE ss_sold_date_sk BETWEEN 2451911 AND 242275;
Internally the system will rewrite and merge all continuous range predicates into a single predicate;
SHOW CUBES;
Cube Name | Table Name | Status | Dimensions | Aggregations | Where Clause
---------------------------------+----------------------------+--------+-----------------------------+-------------------------------------------------------+-------------------------------------------------------+------------------------------
hive.tpcds_sf1.store_sales_cube | hive.tpcds_sf1.store_sales | Active | ss_sold_date_sk,ss_store_sk | sum(ss_sales_price),sum(ss_net_paid),sum(ss_quantity) | (("ss_sold_date_sk" >= BIGINT '2451911') AND ("ss_sold_date_sk" < BIGINT '2452276'))
Note:
The system will try to rewrite all type of Predicates into a Range to see if they can be merged together. All continuous predicates will be merged into a single range predicate and remaining predicates are untouched.
Only the following types are supported and can be merged together.
Integer, TinyInt, SmallInt, BigInt, Date, StringFor String data type, predicate merge logic functionally works only if the Strings are ending with a digit and all are of same length. For example,
INSERT INTO CUBE store_sales_cube WHERE store_id BETWEEN 'A01' AND 'A10';
INSERT INTO CUBE store_sales_cube WHERE store_id BETWEEN 'A11' AND 'A20';
After the insertion, the two predicates will be merged into 'A01' AND 'A20'
SELECT ss_store_id, sum(ss_sales_price) WHERE ss_store_id BETWEEN 'A05' AND 'A15'; - Cube would be used for this query.
Consider the following example where store_id values are not of same length.
INSERT INTO CUBE store_sales_cube WHERE store_id = 'A1';
INSERT INTO CUBE store_sales_cube WHERE store_id = 'A2'
store_id predicate will be rewritten as store_id >= 'A1' and store < 'A3' as per the varchar predicate merge logic;
INSERT INTO CUBE store_sales_cube WHERE store_id = 'A10'
The above query would fail because A10 is subset of the range store_id >= 'A1' and store < 'A3'. So Users should be wary of this issue.
For other data types, it is difficult to identify if two predicates are continuous therefore they cannot be merged together. And because of this issue, there is possibility that particular Cube may not be used during query optimization even if the Cube has all the required data.
- Predicate rewrite has some limitations as well. Consider the following query
INSERT INTO CUBE store_sales_cube WHERE ss_sold_date_sk > 2451911;
The predicate is rewritten as ss_sold_date_sk >= 2451912 to support merging continuous predicates. Since the predicate is rewritten, they query using ss_sold_date_sk > 2451911 predicate will not match with Cube predicate so Cube won’t be used to optimize the query. The same is applicable for predicates with <= operator. ie. ss_sold_date_sk <= 2451911 is rewritten as ss_sold_date_sk < 2451912
SELECT ss_sold_date_sk, .... FROM hive.tpcds_sf1.store_sales WHERE ss_sold_date_sk > 2451911
- Only single column predicates can be merged.
Open issues and Limitations
- StarTree Cube is only effective when the group by cardinality is considerably fewer than the number of rows in source table.
- A significant amount of user effort required in maintaining Cubes for large datasets.
- Only incremental insert into Cube is supported. Cannot delete specific rows from Cube.
- Cubes created on a transaction table may expire automatically even if the source table has not been updated. This is due to the compaction policy which merges delta files into single large ORC file which in turn changes the last modified of time of the table. Cube status is determined by comparing last modified timestamp of table when Cube was created with the last modified time of the table when queries are executed.
- OpenLooKeng CLI has been modified to ease the process of creating Cubes for larger datasets. But still there are limitations with this implementation as the process involves merging multiple Cube predicates into one. Only Cube predicates defined on Integer, Long and Date types can be merged properly. Support for Char, String types still need to be implemented.
- Varchar predicates can be merged only if the values are of same length.
Performance Optimizations on Star Tree
- Star Tree Query re-write optimization for same group by columns: If the group by columns of the cube and query matches, the query is re-written internally to select the pre-aggregated data. If the group by columns does not matches, the additional aggregations are internally applied on the re-written query.
- Star Tree table scan optimization for Average aggregation function: If the group by columns of the cube and query matches, the select query is re-written internally to select the startree cube’s pre-aggregated Average column data. If the group by columns does not match, the select query is re-written internally to select the startree cube’s pre-aggregated Sum and Count column data, from which the average is later calculated.